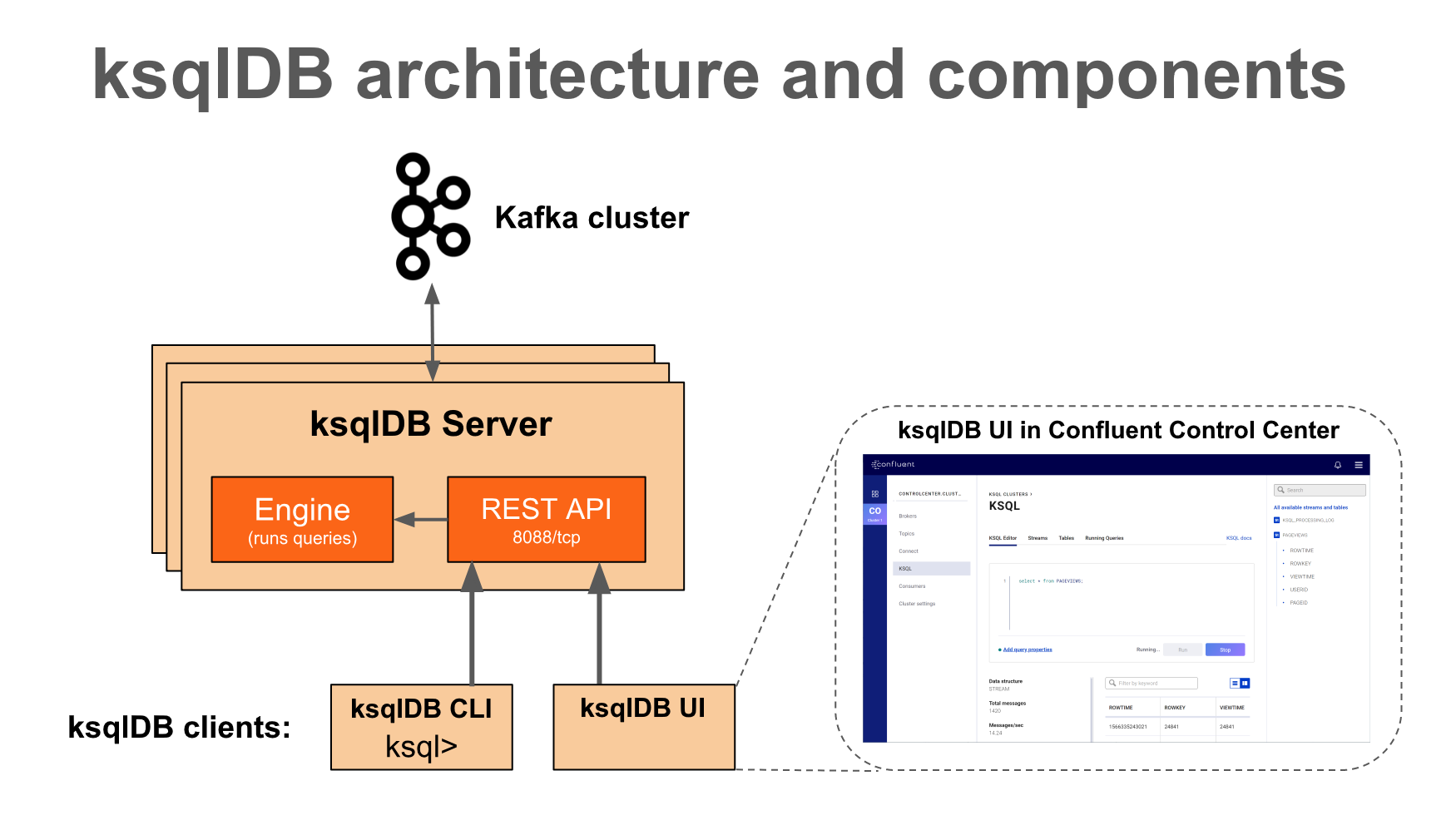
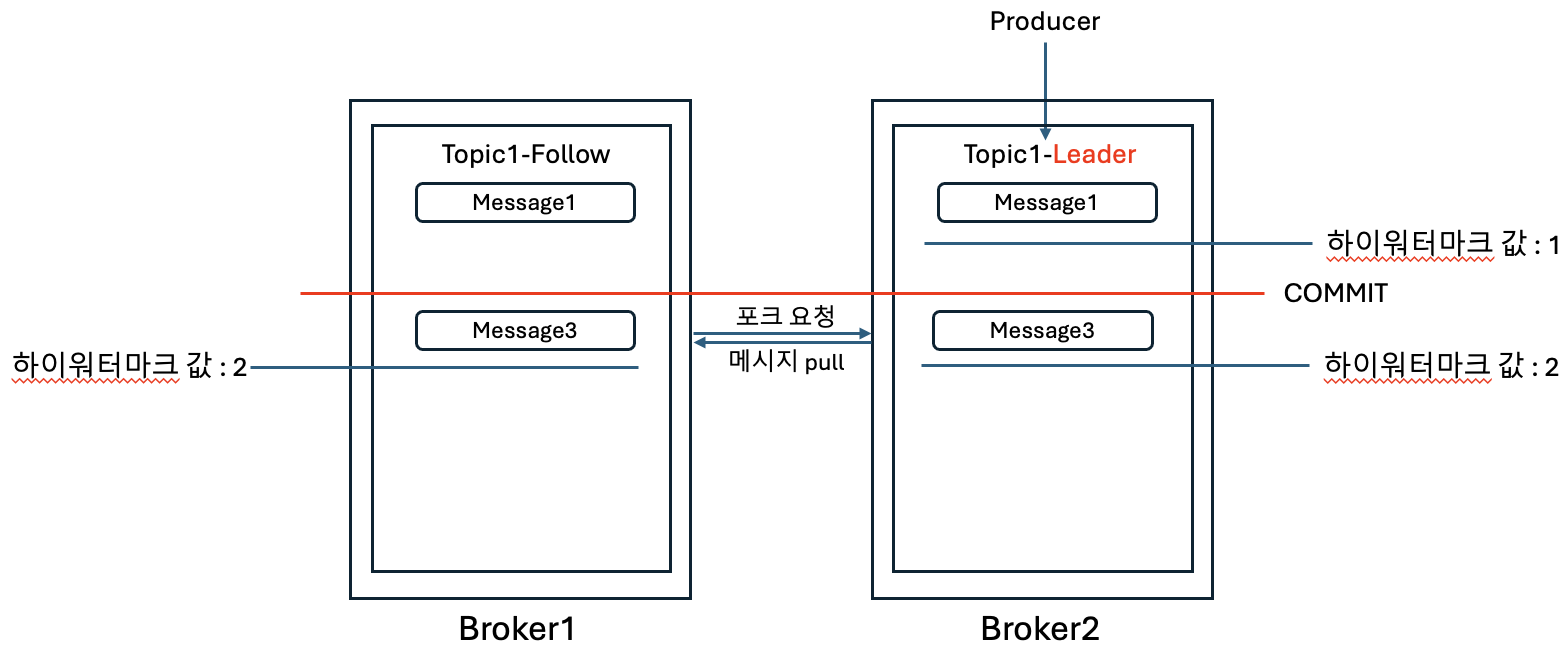
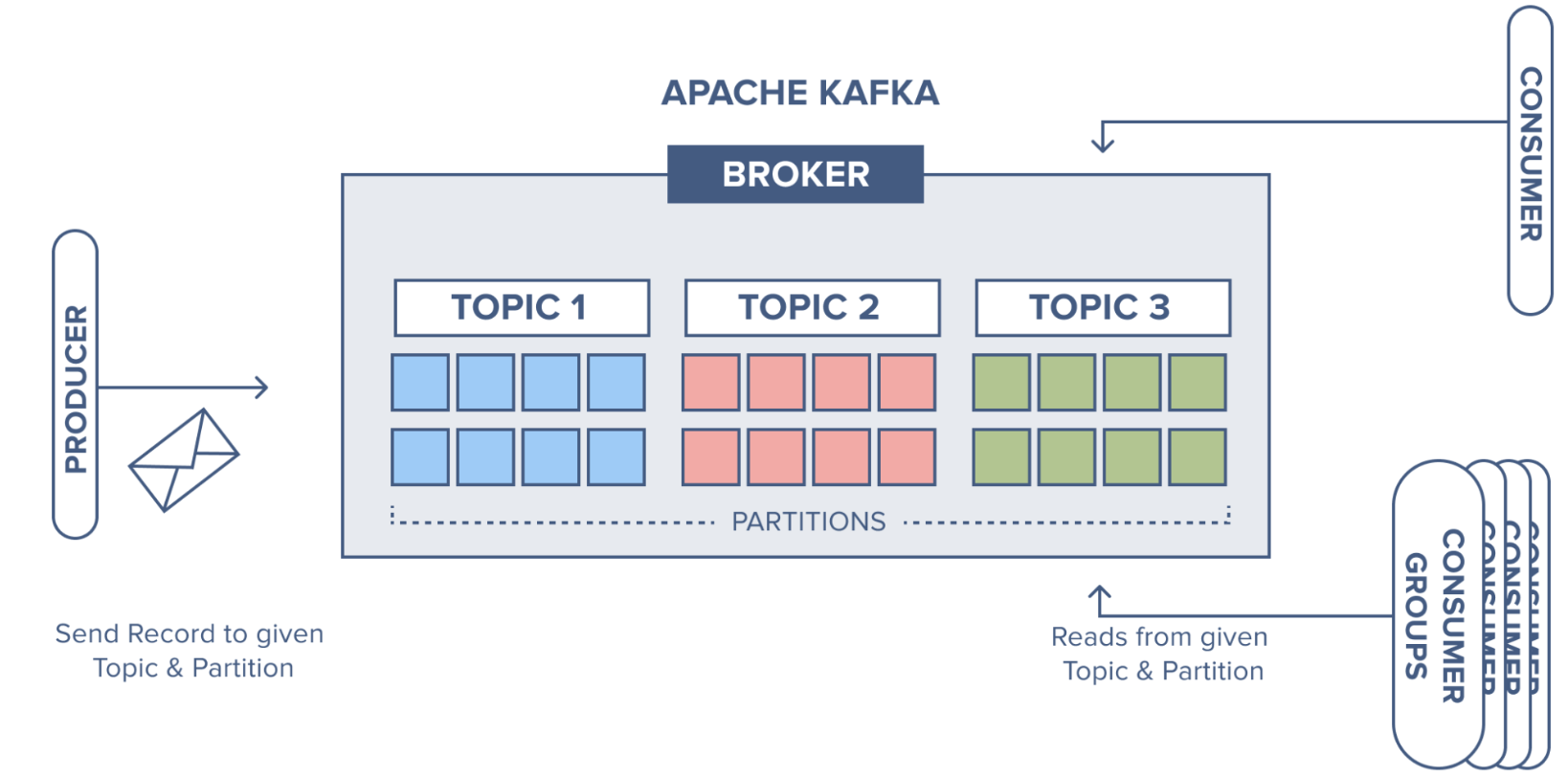
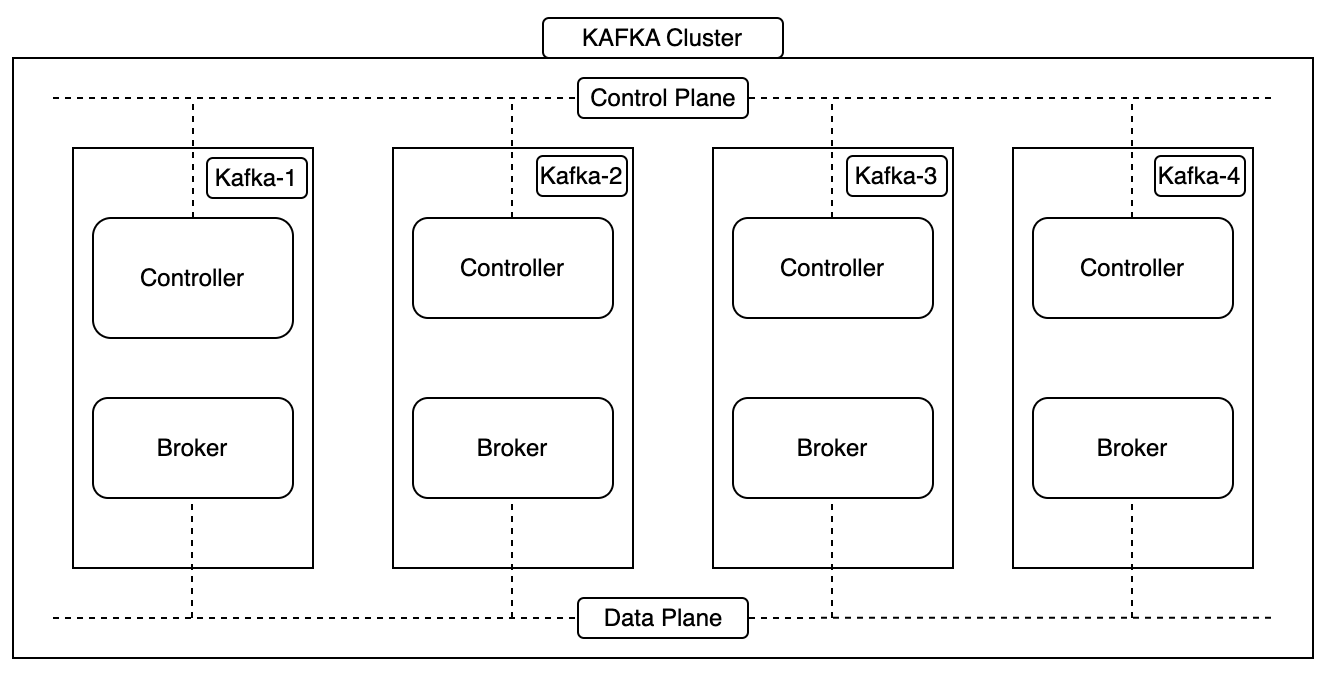
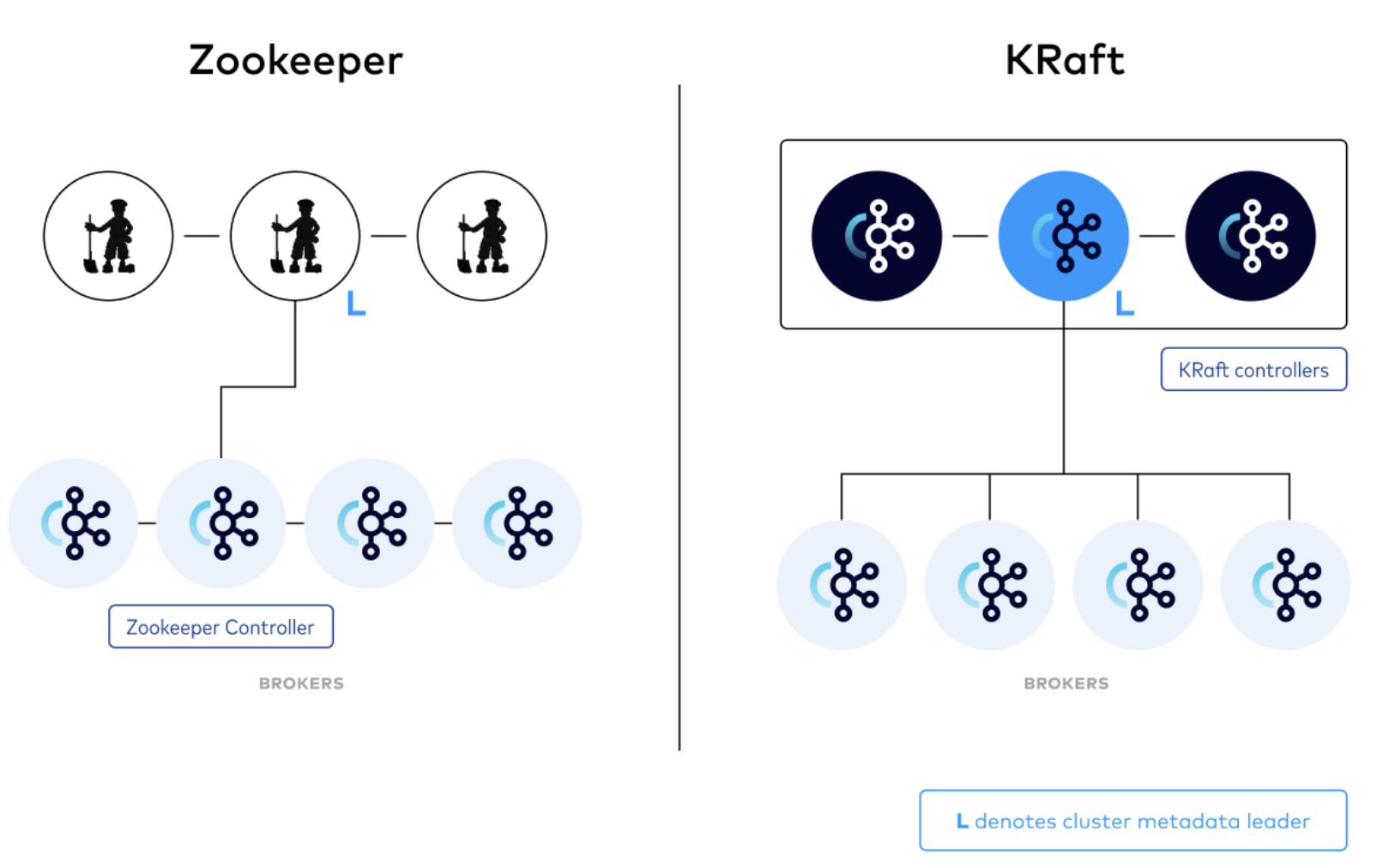
[Kafka] ksqlDB를 사용하여, SQL 구문으로 쉽고 빠르게 카프카 데이터 조회하기 l Kafka 3.6.2, KsqlDB Kafka(이하 “카프카”) 토픽에 저장되어 있는 데이터를 사용하기 위해서는 컨슈머라는 것이 필요하고, 컨슈머에는 각 비즈니스에 필요한 로직을 포함하여 원하는 데이터를 제공한다. 이렇게 시스템을 구성해 놓으면 빠르고 편리하게 메시징 처리를 할 수 있다. 그런데 실시간으로 카프카의 데이터를 조회(집계, 조인)하거나, 카프카 내부의 토픽 데이터를 조합해서 새로운 토픽 데이터 생성이 필요할 때가 있다. 이 경우 매번 컨슈머를 개발하거나 CLI를 통해 구축하는 것은 매우 번거롭고 익숙하지 않은 사용자에게는 어려운 작업일 수 있다. 이때 ksqlDB를 사용하면, 유사SQL문을 사용하여..